感知机原理
感知机原理
感知机模型可以看作一个超平面:
其中
当
时,模型将该样本分为正类
当
时,模型将该样本分为负类
感知器包括多个输入节点,从$x{1}$到$x{n}$,有多个权重矩阵$w{0}$到$w{n}$。一个输出节点$O$,激活函数使用sigmoid函数,最后输出的值为1或者-1。
学习策略
令$M$代表样本点被误分的集合。
所有的被误分类的点都满足:
损失函数为:
优化目标是损失最小化,含义为:最小化误分类点到决策面的距离!
学习算法
随机梯度下降算法(stochastic gradient descent)——每次选取一个被误分类的点,计算损失函数并进行参数更新。
计算梯度:
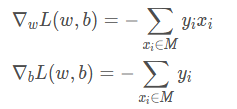
参数更新:
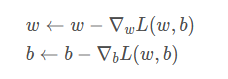
即:
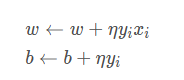
感知器规则解释
输入训练样本X和初始的权重矩阵W,将其进行向量的点乘,按后将求和的结果作用于激活函数sigh(),得到预测输出O,根据预测输出值和目标之间的差距error来调整权重向量W。
如此反复,直到W调整到合适的结果。
使用Python手动实现感知器模型
数据集
- 来源:
sklearn中的鸢尾花(iris)数据集 - 相关任务:分类
- 实例的个数:150个
- 特征的个数:4个
- 有无缺失值:无
- 摘要:Famous database; from Fisher, 1936
数据集介绍
iris数据集是由Fisher在1936年整理,包含四个特征:
- Speal.Length (花萼长度)
- Speal.Width (花萼宽度)
- Petal.Length (花瓣长度)
- Petal.Width (花瓣宽度)
四个特征的类型都为浮点型,单位是厘米。
类别
类别共有三类:
- Iris Setosa(山鸢尾)
- Iris Versicolour(杂色鸢尾)
- Iris Virginica(维吉尼亚鸢尾)
实验说明
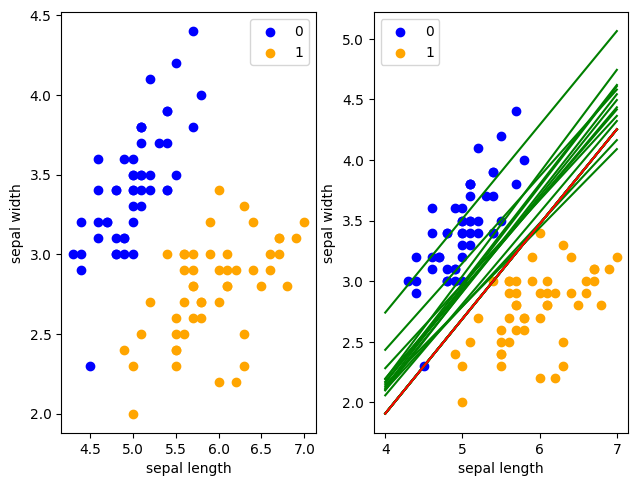
此次感知机实验在Sklearn的Iris数据集拿出两个类别,并以[Speal.Length, Speal.Width]作为特征。
1 | import numpy as np |
1 | class Perceptron(): |
1 | def display(df,x_points,y_,wb): |
1 | #加载数据 |
sepal length sepal width petal length petal width label
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2
[150 rows x 5 columns]
1 | #选取前100个数据,选择的列为第0列,第1列,最后一列(标签) |
[[ 0.23 0.34999996 -0.2 ]
[ 0.41999999 0.31999996 -0.2 ]
[ 0.61000001 0.28999996 -0.2 ]
...
[ 7.83007431 -10.01979733 -12.2 ]
[ 7.83007431 -10.01979733 -12.2 ]
[ 7.83007431 -10.01979733 -12.2 ]]
1 | # 可视化超平面 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 thewindsing!
评论